ScanBot: Autonomous Reconstruction via Deep Reinforcement LearningSIGGRAPH 2023 |
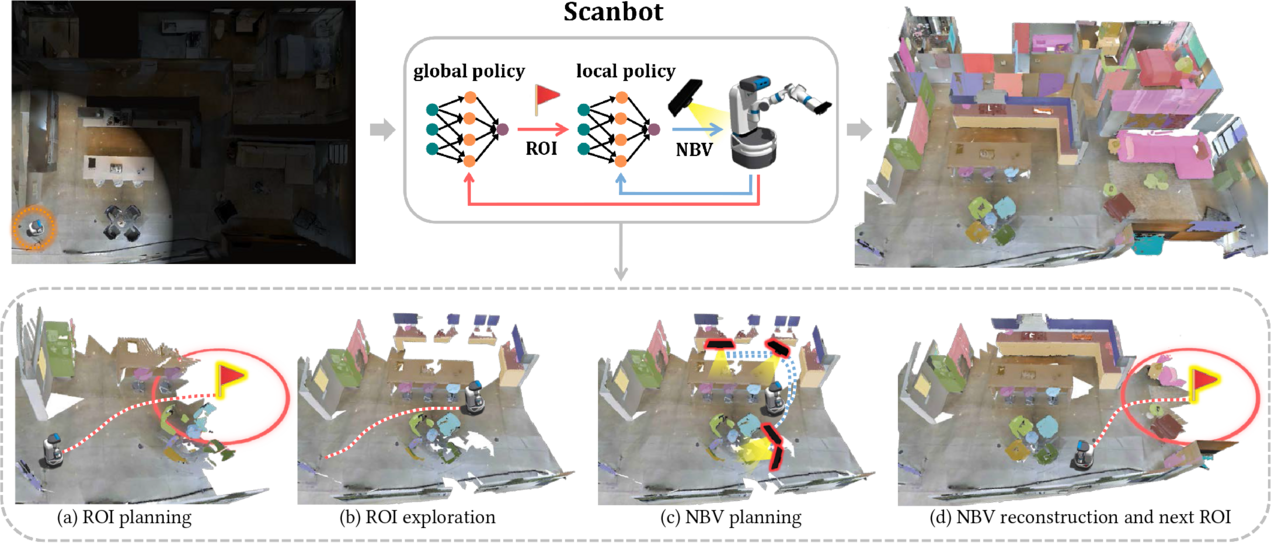
Figure 1: Top: When entering an unknown environment, our proposed ScanBot (circled in orange, left figure) relies on a global policy and a local policy to alternatively generate the region-of-interest (ROI, denoted as a red flag with the red circle) and a series of next-best-views (NBVs, denoted as black Kinect sensors) to automatically reconstruct the scene with object semantics (in different colors, right figure). Bottom: We demonstrate one iteration of the global and local scanning procedures and show their navigation paths using red (global) and blue (local) dotted lines, respectively. ScanBot first selects an ROI by the global policy (a), and then navigates to the goal position (b) to select a sequence of NBVs nearby guided by the local policy (c). When the local detailed reconstruction is finished following the planned NBVs, ScanBot enters the next iteration by selecting a new ROI (d).
Abstract
Autoscanning of an unknown environment is the key to many AR/VR and robotic applications. However, autonomous reconstruction with both high efficiency and quality remains a challenging problem. In this work, we propose a reconstruction-oriented autoscanning approach, called ScanBot, which utilizes hierarchical deep reinforcement learning techniques for global region-of-interest (ROI) planning to improve the scanning efficiency and local next-best-view (NBV) planning to enhance the reconstruction quality. Given the partially reconstructed scene, the global policy designates an ROI with insufficient exploration or reconstruction. The local policy is then applied to refine the reconstruction quality of objects in this region by planning and scanning a series of NBVs. A novel mixed 2D-3D representation is designed for these policies, where a 2D quality map with tailored quality channels encoding the scanning progress is consumed by the global policy, and a coarse-to-fine 3D volumetric representation that embodies both local environment and object completeness is fed to the local policy. These two policies iterate until the whole scene has been completely explored and scanned. To speed up the learning of complex environmental dynamics and enhance the agent's memory for spatial-temporal inference, we further introduce two novel auxiliary learning tasks to guide the training of our global policy. Thorough evaluations and comparisons are carried out to show the feasibility of our proposed approach and its advantages over previous methods.Overview
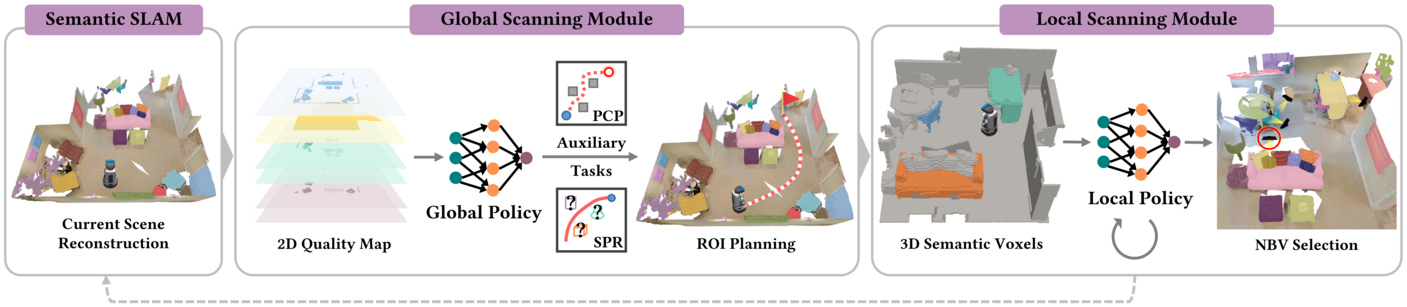
Figure 2: Overview of our DRL-based autoscanning system with global exploratory scanning module and local NBV scanning module. A 2D quality map is constructed from current scene reconstruction and taken as the input to the global policy to generate a ROI to guide the exploration of regions that need finer reconstruction, where the training of the global policy is accelerated by adding two auxiliary tasks. The local policy then progressively selects and scans objects within the ROI by determining a sequence of NBVs. Once all seen objects are reconstructed, the whole process enters the next iteration.
Download
Paper PDF(~8M)Supplementary Material(~1M)
Source Code (Coming Soon)
Presentation Video
Results
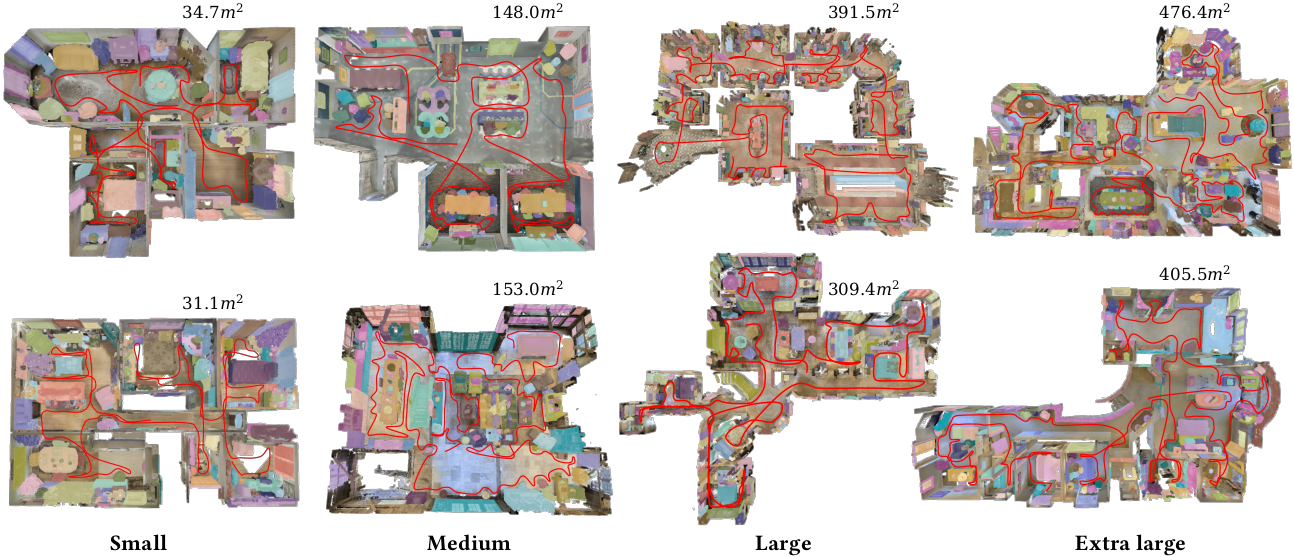
Figure 3: Visual results of simulated scanning in different splits of the test set.
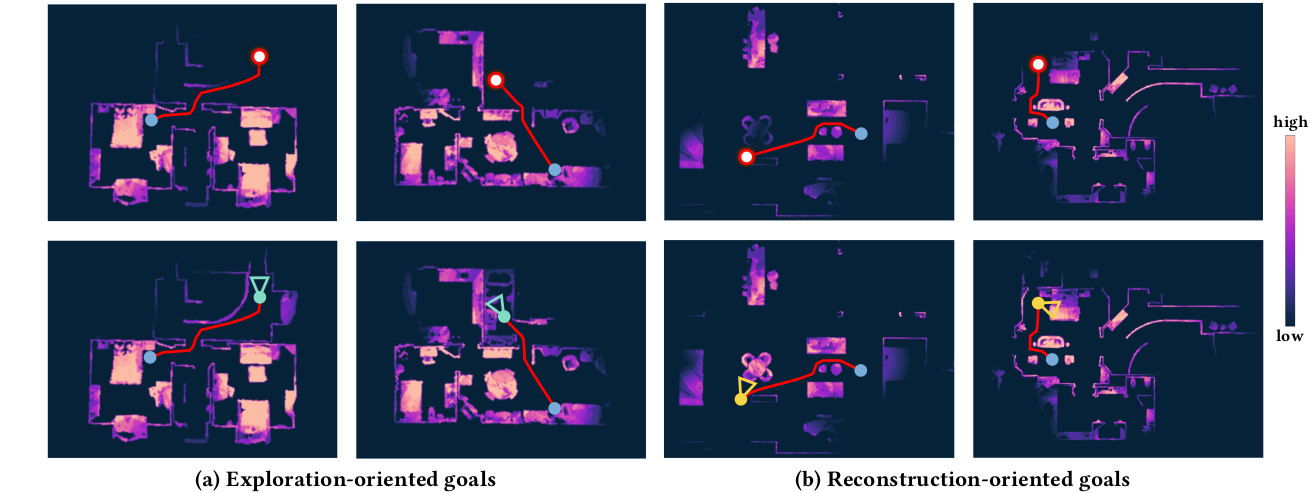
Figure 4: Example goal points (red circles) generated by our global policy. For each example, the input quality map with blue dot for start point and red line for navigation path is shown on the top, and the one obtained after the ScanBot (cyan/yellow camera icons) arrives the ROI is shown on the bottom. (a) Two exploration-oriented goals that help explore unknown area and expand the boundary efficiently. (b) Two reconstruction-oriented goals that help increase the reconstruction quality of discovered objects.
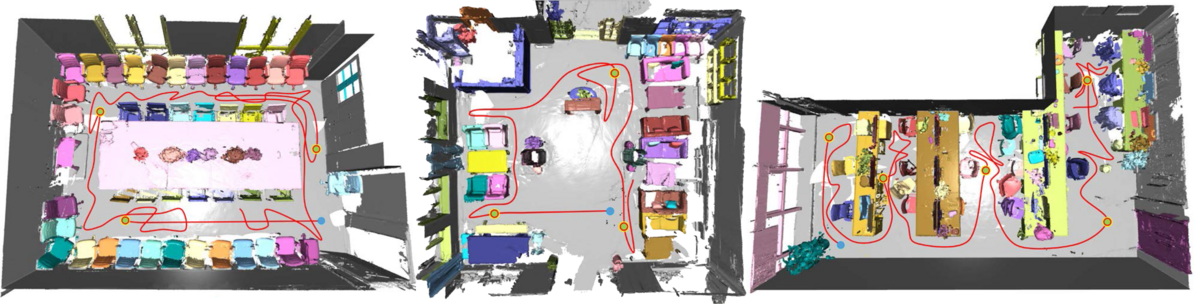
Figure 5: Example results of directly adapting our method for real-world scene reconstruction with blue dots for start points, red circled points for planned ROI, and red lines representing navigation paths.
Acknowledgments
We thank the anonymous reviewers for their valuable comments and suggestions. This work is supported by the National Key R&D Program of China (2022YFB3303400), National Natural Science Foundation of China (62025207), Guangdong Natural Science Foundation (2021B1515020085), and Shenzhen Science and Technology Program (RCYX20210609103121030).
Bibtex
@article {cao2023scanbot,author = {Hezhi Cao, Xi Xia, Guan Wu, Ruizhen Hu, and Ligang Liu},
title = {ScanBot: Autonomous Reconstruction via Deep Reinforcement Learning},
journal = {ACM Transactions on Graphics (SIGGRAPH 2023)},
volume = {42},
number = {4},
year = {2023}}
